
An smart detection benchmark for mixed smart and human writing should reflect what happens in real editorial work, not just compare untouched machine drafts with fully human copy. In practice, writers and editors revise introductions, reshape structure, add reporting, swap examples, and cut predictable phrasing. By the time a piece is ready for review, it often contains a blend of sources rather than a clean single origin. If you want background on that process, start with how detection works after human editing.

That is why a useful benchmark is less about proving authorship with certainty and more about measuring behavior on labeled samples. Publishers, marketers, and compliance teams need to know where detectors become unreliable, how often edited text is flagged by mistake, and when human review should override a score. A strong benchmark helps teams compare tools, set realistic thresholds, and create fairer standards for mixed-origin drafts.
Why mixed-origin writing breaks simple detection tests
Basic tests usually compare two neat groups: untouched machine-generated text and clearly human-written text. That setup is easy to score, but it misses the messy middle where most real decisions happen. Once a person rewrites sentence flow, adds facts, removes generic transitions, or blends original reporting into a draft, the final piece no longer behaves like either extreme. As a result, mixed human and machine-generated writing detection accuracy often falls in ways a simple benchmark never shows.
Labels also get harder after revision. A draft may start from generated copy, yet end up carrying mostly human wording, examples, and judgment. If that sample is still labeled as fully machine-written, the final score can make a detector look stronger than it really is. A credible benchmark has to reflect how content is actually drafted, revised, reviewed, and published.
Heavy human revision weakens many signals these systems tend to rely on, such as even sentence rhythm, repeated phrasing, and predictable transitions. Editors introduce variation, sharper points of view, domain detail, citations, and occasional roughness that make text read more like ordinary authored work. Some samples also become hybrids in a very literal sense, such as a human-written introduction attached to lightly edited generated body paragraphs. If a benchmark ignores edit depth or section-level variation, it can hide both false positives and false negatives and leave teams with a misleading sense of confidence.
How to build a fair benchmark for edited and blended text
If you want to know how to benchmark detection after human editing, start with balanced sample groups and labeling rules that are easy to explain. Include untouched human writing, untouched machine-generated writing, lightly edited drafts, heavily rewritten drafts, and truly blended documents that combine multiple sources. Keep sample length reasonably consistent, record how the edits were made, and note whether changes were structural, stylistic, or factual. That creates a benchmark dataset for blended writing detection that looks more like real editorial output and less like a lab exercise.
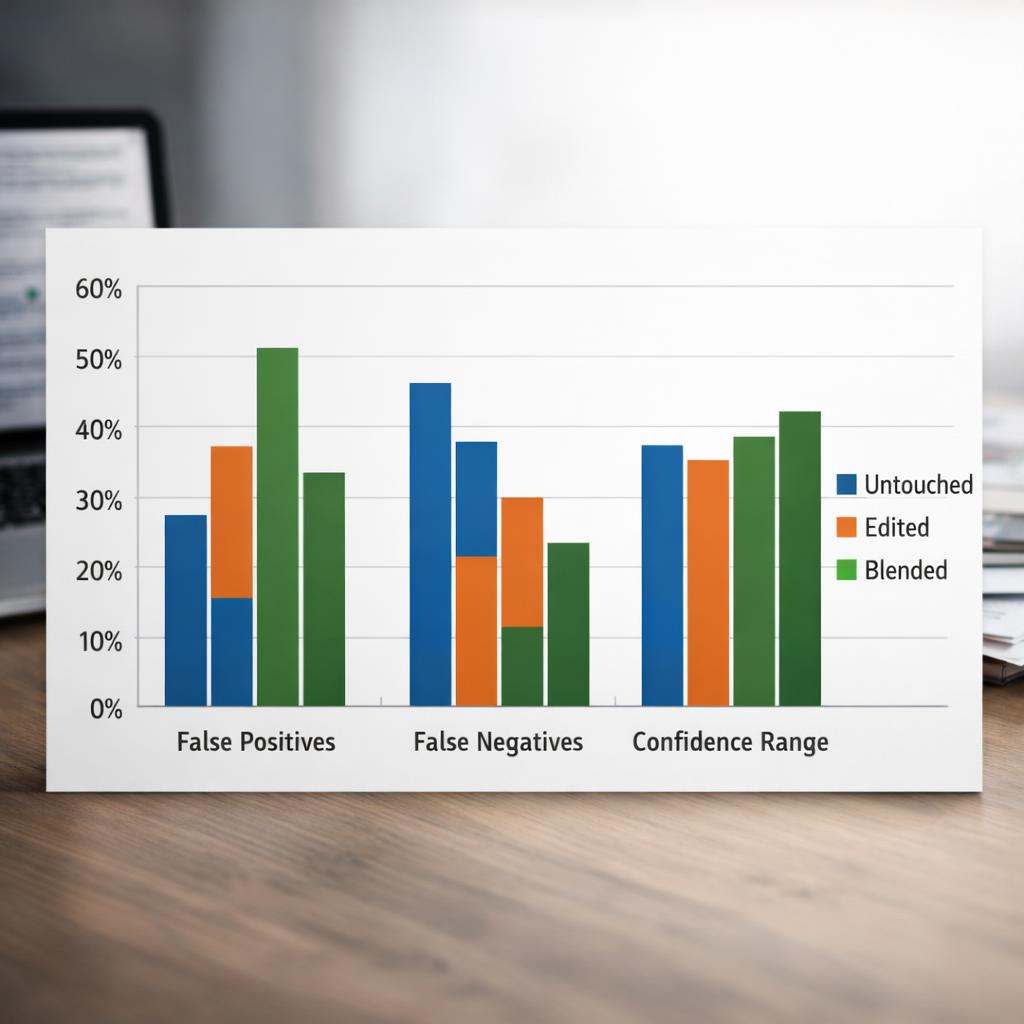
Scoring should go beyond one headline accuracy number. Track false positives, false negatives, confidence ranges, and performance by category. Teams should also record who labeled each sample and what rule they used for partial rewrites. For example, was the label based on the starting source, the final wording, or the percentage of text still preserved? Those decisions shape the outcome, so they should be visible to anyone reading the results.
A practical benchmark often benefits from a simple review table for every sample: source type, editing depth, estimated retained text, final use case, and detector score. This makes it easier to separate “edited from generated writing” from “blended from several sources,” which are related but not identical cases. It also helps during audits, when editors or stakeholders want to know why a result looked wrong.
False-positive tracking deserves extra attention because it often creates the biggest business risk. A tool that wrongly flags polished human work can slow approvals, frustrate writers, and trigger unnecessary disputes. That is why many teams pair benchmark data with manual review rules and internal guidance on false positives after revision. The benchmark should support that workflow, not replace judgment.
How to read benchmark results without overclaiming accuracy
Benchmark results should be treated as evidence about performance on a labeled test set, not proof that a detector can identify origin in every case. Look past the top-line score and focus on confidence ranges, category-level performance, and failure patterns. A tool that performs well on untouched samples but struggles with heavily revised drafts may still help with triage, but it should not be used alone for high-stakes decisions. On the other hand, a lower overall score may be acceptable if false positives on human writing stay low enough for your review process.
Edge cases usually reveal more than headline numbers. Mixed sections, partial rewrites, translated drafts, and heavily edited marketing copy often expose where a detector becomes uncertain. The best readout combines benchmark data with practical guidance: when to escalate a review, when to request draft history, and when to treat a score as too uncertain to act on. That keeps the smart detection benchmark for mixed smart and human writing tied to real publishing decisions instead of inflated claims.
Teams should also align the benchmark with the use case. Marketing copy, news features, product pages, and academic submissions all have different writing patterns and different tolerance for error. A framework can be shared across settings, but the sample set, labels, and acceptable false-positive rate should match the actual review environment. That is what makes benchmark results useful rather than merely impressive.

Conclusion
A useful smart detection benchmark for mixed smart and human writing measures edited reality, not a simplified contest between pure generated text and pure human authorship. The strongest benchmarks use balanced categories, transparent labels, and category-level reporting so teams can see how revision changes outcomes. They also recognize a practical limit: benchmark scores show likelihood and system behavior on labeled samples, not certainty about where every sentence came from.
For publishers, marketers, and review teams, that distinction is what makes benchmark data actionable. When you measure false positives carefully, account for deep rewriting, and connect results to clear review steps, you get a standard that is fairer to writers and more useful for policy decisions. Used this way, benchmark data becomes a guide for better review, not a shortcut to overconfident claims.
FAQ
How should a benchmark label partially rewritten drafts?
Use a rule that is explicit, repeatable, and easy to audit. Many teams label by edit depth or by the share of wording retained from the starting draft, then report those groups separately instead of forcing a single binary label. That makes the findings easier to trust and compare.
Why do false positives increase after heavy human editing?
Some revised drafts keep traces of their original structure, while others become stylistically uneven in ways that confuse detectors. That overlap can lead a system to flag text that now reads mostly like ordinary human writing, especially when sections were edited at different depths.
What metrics matter most besides overall accuracy?
False-positive rate, false-negative rate, confidence distribution, and category-level performance usually matter more than one summary score. Those metrics show where the detector fails, how often uncertainty appears, and whether the errors create real workflow risk.




