
Yes, but only sometimes. Detectors can still flag humanized machine-written essays when the edits are light, repetitive, or mostly cosmetic. If the draft is deeply rewritten with a new structure, stronger evidence, and clearer original reasoning, detection becomes less reliable. For a broader framework, see how detection works after human editing.

The key takeaway is practical: detector results are clues, not proof. Students, educators, and reviewers should look at how much the text changed, whether the essay shows real thought and source use, and whether the writing history supports authorship. Those checks matter more than treating one score as a final judgment.
Direct answer: yes, but only when the edits are limited or patterned
Can smart detectors detect humanized smart essays? In many cases, yes. If someone keeps the same sentence order, argument flow, transitions, and paragraph rhythm from a machine-written draft, the edited version may still carry similar patterns. That is why detectors sometimes continue to flag rewritten text even after a person swaps words, shortens sentences, or adds a few personal touches. It is also why people ask whether detectors can catch rewritten essays after human editing. The answer usually depends on how much of the original writing pattern is still there.
Why heavily rewritten essays may look more human while still leaving detectable signals
A deep rewrite can lower detection confidence, but it does not guarantee a clean result. Some signals may remain, such as very even sentence predictability, generic idea development, or polished claims without much support. At the same time, real human revision often adds stronger signs of authorship: uneven phrasing, selective emphasis, sharper examples, and a more natural mix of sentence lengths. In most cases, the more a writer rebuilds the draft instead of polishing it, the less certain the detector becomes. That is why any conclusion should stay conditional.
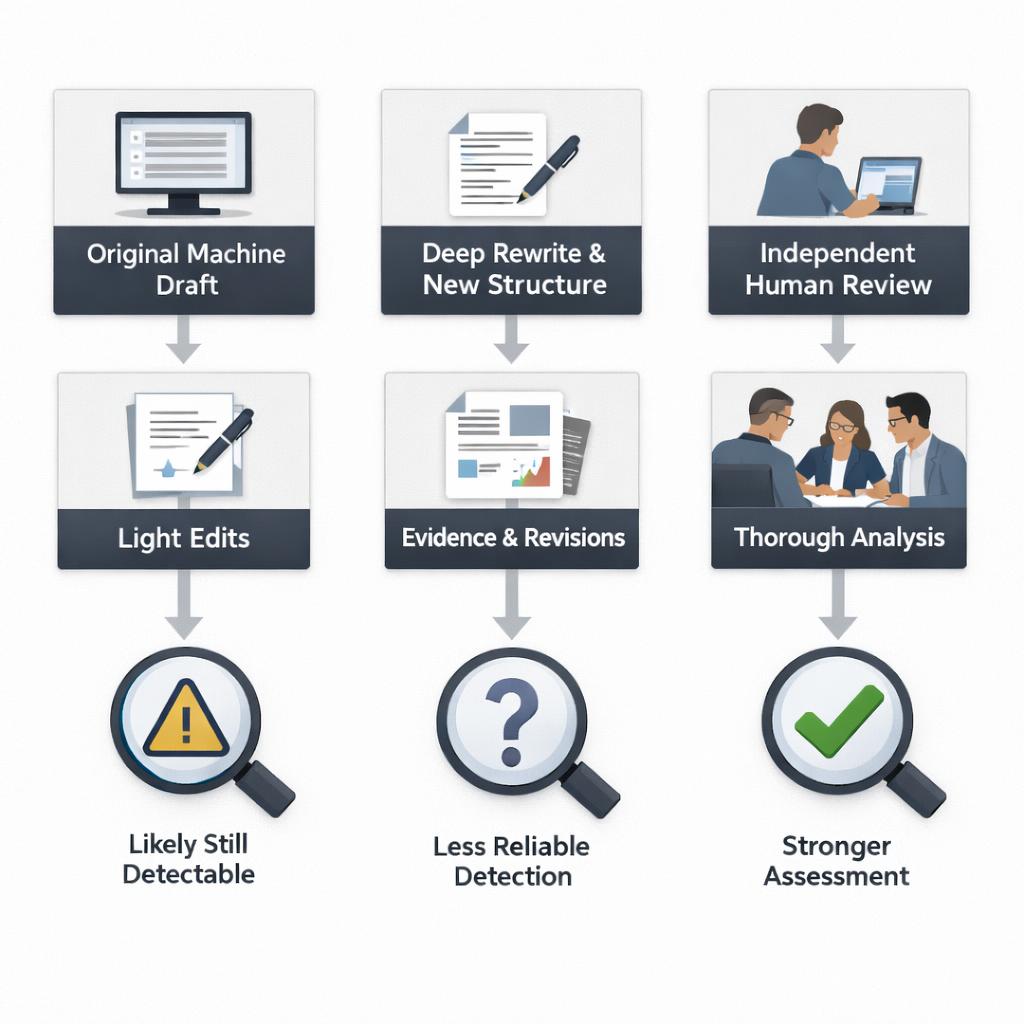
What detectors check after human editing
Most systems do not know who actually wrote the essay. They only inspect the text and estimate whether its patterns resemble machine-written language. After human editing, detectors may still react to predictable wording, highly balanced sentence structure, repeated transition habits, and a lack of distinctive reasoning. They may also pick up on inconsistencies, such as a polished introduction followed by weak source integration, or a sudden style shift from one section to another. In other words, detection after human editing is usually pattern matching rather than direct evidence of authorship.
Text patterns, consistency shifts, and source verification limits
Detectors are generally strongest when the edits are shallow and the underlying draft stays mostly intact. They are weaker when a person rebuilds the argument, changes the structure, replaces examples, and uses verifiable citations in a meaningful way. Source verification matters because many tools cannot tell whether the writer truly understood the sources or simply inserted them. A score can suggest that a passage looks machine-written, but it cannot reliably prove intent, process, or originality without more context such as revision history, notes, earlier drafts, and citation checks.

When detection is useful, when it fails, and what to do next
Detection works best as a screening step, not as a stand-alone decision tool. It is most useful on lightly edited drafts, formulaic essays, and submissions that show little independent thinking. It tends to fail more often on deeply rewritten essays, writing from non-native speakers, heavily edited student work, or highly standardized academic prose. That is where false positives in detector results become a real concern. A fully human essay can be flagged simply because clear, predictable writing sometimes overlaps with machine-like patterns.
Best-fit use cases, false-positive risks, and safer review steps
A safer review process combines detector output with other signals:
- Drafting history and document version changes
- Metadata and writing timeline when available
- Citation accuracy and source relevance
- Whether the essay actually fits the assignment
- Whether the writer can explain the argument and evidence
The strongest recommendation is to use detection as one input within a broader review process. A secondary recommendation is to compare structure changes and evidence use before drawing conclusions. What the available evidence does not support is any guaranteed accuracy rate or a universal point where detection always fails. If you need a repeatable framework for this scenario, the guidance in how detection works after human editing is worth comparing because it focuses on practical review factors rather than relying on one score alone. You can also use a human review checklist for flagged writing to judge whether the essay shows authentic revision instead of surface-level paraphrasing.

Conclusion
So, can smart detectors detect humanized smart essays? Yes, but reliability drops as the rewriting becomes deeper, more original, and better supported with real evidence. Light edits often leave enough patterned language for detectors to react, while full rewrites weaken those signals and increase uncertainty. That is why detector scores should be treated as indicators, not proof.
If you need to judge a humanized machine-written essay fairly, compare the detector result against writing history, citation quality, structural changes, and the writer’s ability to explain their sources and argument. Then review the broader framework in how detection works after human editing and verify the specific dimensions that matter next: revision depth, source use, consistency across drafts, and false-positive risk.
FAQ
Can a heavily edited machine-written essay still be detected?
Yes, sometimes. If the rewrite keeps the same logic, paragraph sequence, and general phrasing patterns, detectors may still flag it. If the writer substantially changes the structure, argument, examples, and source use, the result often becomes less reliable. In that situation, a flag should lead to further review, not an automatic conclusion.
Why do detectors sometimes flag fully human writing?
Human writing can be clear, formulaic, and predictable, especially in academic settings. That overlap creates false positives. Writers who use simple sentence patterns, standard transitions, or tightly structured formats may appear suspicious even when they wrote everything themselves. That is why context, revision history, and source discussion matter so much.
What should reviewers check besides the detector score?
Reviewers should look at document history, draft progression, citation accuracy, assignment alignment, and whether the writer can explain how the argument was developed. When appropriate and allowed, they can also compare the essay’s voice with prior work. The most defensible decisions come from combining multiple signals rather than overtrusting one detection result.




