
Yes, but only in limited situations. Some detectors can flag DeepSeek-written drafts with decent screening value when the text is long, lightly edited, and tested in a format the tool handles well. Even then, the result is not proof. Scores can shift based on prompt style, model version, language, topic, and how much a person revised the draft afterward.

For SEO teams, the more useful question is not just whether can smart detectors detect deepseek output accurately, but whether a detector is dependable enough for real editorial work. In most cases, the answer is: helpful for triage, risky as a final judgment. If you are comparing options for publishing workflows, it also makes sense to review best detection tools for SEO publishers once you know how much uncertainty your team can accept.
Direct Answer: Yes, but only under limited conditions
Detectors are most likely to work when a draft stays close to its original machine-written form. Longer passages, generic wording, and predictable structure give these tools more material to analyze. That is why some editors use them as an early screening step for contributor submissions, outsourced articles, or large batches of content that cannot be reviewed line by line right away.
But the limits show up fast. Accuracy usually drops when the passage is short, heavily revised, translated, or blended with human writing. A technical article written in a niche voice may also confuse the tool. In practice, two detectors can score the same passage very differently, which is why any direct answer has to stay conditional. Yes, detection is possible, but only when the content and testing setup are favorable.
Why false positives and false negatives still happen
False positives happen because detectors often react to traits that also appear in legitimate human writing: clean grammar, repeated sentence rhythms, formal tone, and standard structure. A well-edited product page or policy article may look suspicious even when a person wrote every word. False negatives happen for the opposite reason. If someone rewrites the draft, changes sentence flow, adds expertise, or mixes in original reporting, the detectable patterns may weaken enough that the tool no longer flags it.
That is the main reason scores should be treated as signals instead of verdicts. A high score may justify a closer look, but it should not automatically trigger rejection, penalties, or authorship claims without other evidence.
How SEO Publishers Should Judge Detection Results
Start with workflow fit rather than marketing claims. A detector is valuable if it helps editors review risk more consistently, keeps false alarms manageable, and explains results clearly enough that people can act on them. For many publishers, the best use case is intake screening: reviewing first drafts from freelancers, checking outsourced content, or prioritizing which pages need extra editing before publication.
It is much less suitable as stand-alone proof in disputes. If a writer challenges a score, or if a team needs to decide whether a draft should be rejected, a detector alone is usually too weak to settle the issue. Human review still matters, especially when the text is short, specialized, or obviously revised by an editor.
A better approach is to test tools against your own material. Build a sample set that includes known human articles, raw generated drafts, and edited versions of those drafts. Then compare how each detector behaves across the same pieces. You are looking for repeatability, not just one impressive result. If scores swing wildly after small edits, the tool may still have value for manual review, but it is not stable enough to trust on its own.
A simple fit check for editorial workflows
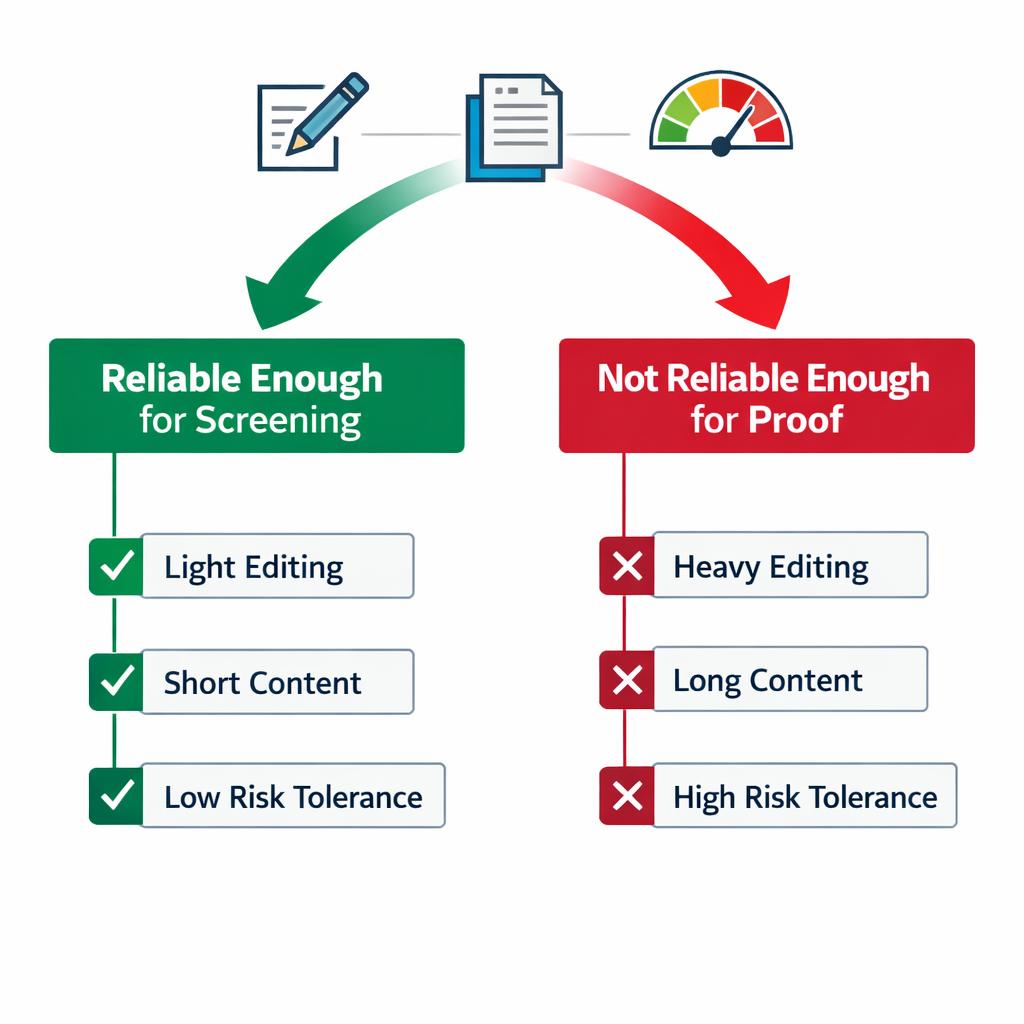
A practical system is to place results into three buckets:
- Screening useful: catches lightly edited generated drafts often enough to save editor time, while rarely flagging normal human work.
- Needs manual review: produces mixed or unstable scores, so editors should use it only as a prompt to inspect the draft more closely.
- Not reliable enough for proof: reporting is vague, repeat tests vary too much, or the tool overflags polished human content.
This framework helps teams avoid the common mistake of asking a detector to do more than it reasonably can. The goal is not perfect identification. The goal is better editorial triage with fewer bad decisions. Pairing detector results with an editorial review process for generated content usually leads to better outcomes than relying on a score alone.

What to Compare Before Trusting Any Detection Tool
Before you rely on any detector, compare a few practical dimensions that matter in real publishing environments.
Key comparison points before you choose
- False-positive behavior: Test known human content from your own site. This matters because a detector that regularly flags clean human writing will quickly lose editor trust.
- Consistency after edits: Run the same draft before and after light revision. If a small rewrite causes a huge score swing, the result may be too fragile for policy decisions.
- Coverage by language and format: Check whether the tool handles short posts, product descriptions, landing pages, and long-form articles. Some tools look better on essays than on real SEO page types.
- Reporting clarity: Editors need to understand what the result means, what the confidence level is, and where uncertainty remains.
- Workflow fit: Bulk checks, exports, team access, and API support may matter more than headline accuracy claims if you review content at scale.
If you are building a shortlist, it is worth comparing broader first-party solutions and established detection products because they may offer lower setup friction, clearer reporting, or easier batch review for editorial teams. They are worth comparing not because any one tool can prove authorship, but because some are simply better matched to high-volume publishing, contributor screening, and repeatable review policies.
Keep evidence boundaries clear when you evaluate recommendations. Your primary recommendations should be the tools you tested on your own sample set. Secondary recommendations are the ones that seem promising based on format support, reporting, or workflow features and deserve a trial. Exploratory options are related tools that may be useful later but do not yet have enough evidence from your environment.
That distinction matters because no limited test can prove universal accuracy across every DeepSeek prompt, every niche, or every level of editing. So if you are still asking whether can smart detectors detect deepseek output accurately, the most honest answer remains: sometimes well enough to help editors, but not well enough to replace them.

Conclusion
The practical answer is yes, sometimes, but not reliably enough to stand as proof by itself. Detectors tend to perform best on longer, lightly edited DeepSeek drafts and worst on short, revised, or mixed-authorship content. For publishers, that makes them useful as screening tools, not final judges.
Your next step should be specific: compare detector candidates on your own sample set for false positives on human-written pages, consistency after edits, language and format coverage, and reporting clarity. Then review best detection tools for SEO publishers to narrow the list to options that fit your editorial volume, review process, and risk tolerance.
FAQ
Can text detectors reliably identify DeepSeek content?
Sometimes, but mostly for screening rather than proof. They tend to perform better on long, lightly edited drafts and worse on short, heavily revised, translated, or mixed-authorship content. For most publishers, “reliable” means useful for triage, not strong enough to settle disputes.
Why do detectors mislabel human writing as generated text?
Because the patterns they flag are not exclusive to generated text. Human writing can also be formal, predictable, concise, or repetitive, especially in product pages, policy content, and standardized web copy. That is why scores need context, revision history, and editorial review.
What is the best way to test detection tools for an SEO publishing team?
Use your own content mix: known human articles, raw generated drafts, and edited versions of those drafts. Compare false positives, repeatability, reporting clarity, and how well each tool fits your workflow. If you want a next step, compare shortlisted tools by false-positive rates, stability after revision, page-type coverage, and export or API support before adopting one.




